AWS Glue is a serverless ETL service offering that has a pre-built Apache Spark environment for distributed data processing. It makes developers life easy; simply write code and execute while AWS Glue take care of managing infrastructure, job execution, bookmarking & monitoring. That being said, AWS Glue is not just a managed Spark cluster, it has a component library for most common ETL tasks. But the challenge is how to leverage such capabilities during our local development. Fortunately, it is possible and I am happy to share my learning.
Why do I care about local development ? I have a strong opinion that a platform or service offering without local development and debugging toolkit could increase the development effort by orders of magnitude. As a developer, I worked on platforms where the local testing was not possible so I had to go through repeated cycles of develop, deploy & test for a small change that took days to complete. If I had an option to develop & debug locally, the same task could have been done in few hours.
Therefore, developer productivity is an important factor to consider when choosing a platform or managed service.
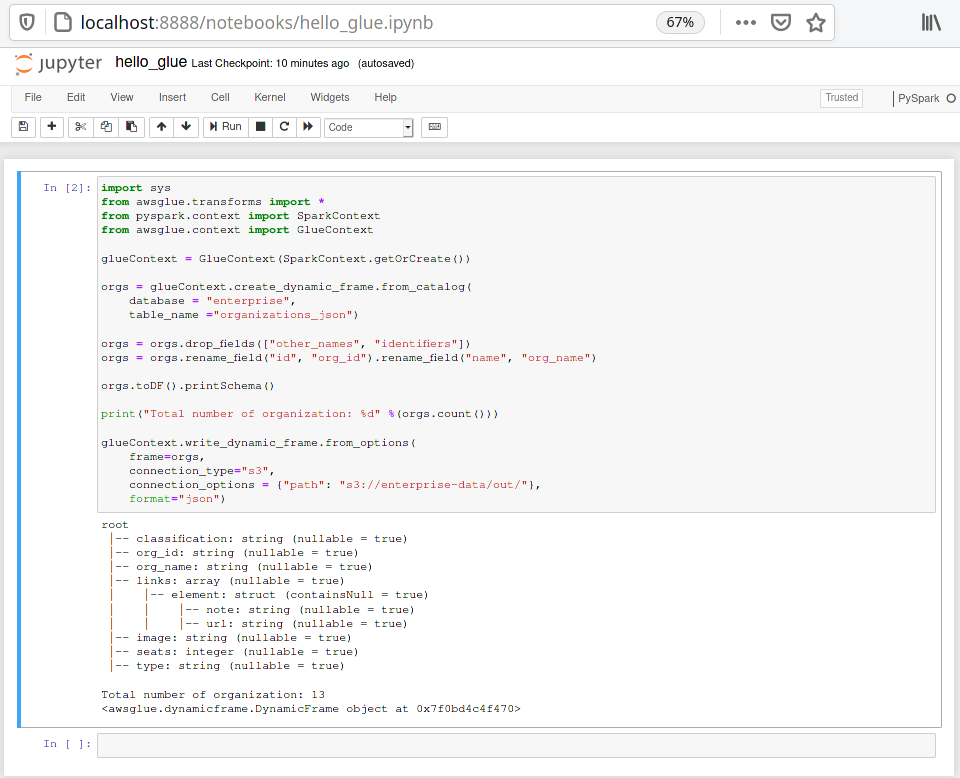
Decoding Glue code snippet: To better understand the glue dependencies at development time. Lets take a look at the simple AWS glue code snippet below.
from awsglue.transforms import *
from pyspark.context import SparkContext
from awsglue.context import GlueContext
# Create a Glue context using spark session
glueContext = GlueContext(SparkContext.getOrCreate())
# Extract: Create a dynamic dataframe from the glue catalog table
orgs = glueContext.create_dynamic_frame.from_catalog(
database = "enterprise",
table_name ="organizations_json")
# Transform: Apply glue transformations on the dyanamic dataframe
orgs = orgs.drop_fields(["other_names", "identifiers"])
orgs = orgs.rename_field("id", "org_id").rename_field("name", "org_name")
# Transform: Convert dynamic dataframe to spark dataframe
# to leverage spark capabilities such as UDF, Spark SQL & functions
orgs.toDF().printSchema()
# Load: Store the transformed data into target store such as s3
glueContext.write_dynamic_frame.from_options(
frame=orgs,
connection_type="s3",
connection_options = {"path": "s3://enterprise-data/out/"},
format="json")At the high level, the code extracts data from AWS Glue catalog table, apply transformations and load the result into S3 bucket. But I would like to discuss few details.
- Dynamicframe: AWS Glue introduced an abstraction on top of Spark dataframe to improve the performance as well as to have finer control on handling schema discrepancies. All Glue built-in components take and/or produce dynamicframe.
- GlueContext: A wrapper over Spark context that enable us to read, modify and write dynamicframe. GlueContext is required for any operations that deals with dynamicframe. Though Spark provides native support for reading and writing data from S3, RDBMS & NoSQL, I am not certain that Glue catalog can be accessed without GlueContext.
- Glue Transforms: Glue component library includes transform components such as
drop_fields,rename_field,filter,select_fieldsandapply_mapping. They come in handy to apply directly on dynamicframe.
Having said that AWS Glue does not restrict one from using Spark features. One can convert dynamicframe to spark dataframe, leverage spark features and convert back to dynamicframe if deemed necessary.
AWS Glue and Apache Spark make a powerful combo to simplify ETL development & execution. To have a good developer experience, need development toolkits of both for local setup.
Local development setup
There are at-least two options for setup a local environment.
- Developing locally with Python/Scala
- Developing locally using Glue docker image
In this blog post, I would like to cover the local setup using Docker image. The Glue docker image simplified the local setup, takes no time to get started with the development. I would strongly recommend it to anyone who wants to learn Glue or do a quick assessment.
What is inside the image? The image is bundled with glue-libs (incl. component library, gluecontext), custom Spark distribution for Glue and notebook tools (Jupyter and Zeppelin) for ETL development.
For a local setup using Glue docker image, make sure the following prerequisites are met.
- Docker installed
- AWS credentials configured (for AWS services interaction e.g. S3)
- Free disk space of at-least 7 GB
Complete the setup with a command
docker run -itd -p 8888:8888 -p 4040:4040 -v $HOME/.aws:/root/.aws:ro \
--name glue_jupyter amazon/aws-glue-libs:glue_libs_1.0.0_image_01 \
/home/jupyter/jupyter_start.shwhere
4040:4040- Refers to Spark UI port8888:8888- Refers to the port to access Jupyer notebook$HOME/.aws:/root/.aws:ro- Mounts aws credentials from local to container
If you connect internet via proxy server, make sure you set environment variables for HTTP_PROXY, HTTPS_PROXY & NO_PROXY as below
docker run -itd -p 8888:8888 -p 4040:4040 -v $HOME/.aws:/root/.aws:ro \
-e HTTP_PROXY=$HTTP_PROXY -e HTTPS_PROXY=$HTTPS_PROXY -e NO_PROXY=$NO_PROXY \
--name glue_jupyter amazon/aws-glue-libs:glue_libs_1.0.0_image_01 \
/home/jupyter/jupyter_start.shhttp://localhost:8888 to begin development
For Zeppelin notebook
- Replace the port 8888 with 8000
- Replace the command
/home/jupyter/jupyter_start.shwith/home/zeppelin/bin/zeppelin.sh
Caveat: Glue docker image is not actively managed. The latest image available is for Glue 1.0 and the last update was made a year ago. Currently, Glue 2.0 image is unavailable and unable to find Glue 1.0 image source (i.e. Dockerfile) to contribute back.
Conclusion: I am quite impressed with the local development experience using Glue docker image. It serves my need for now. For large-scale application development, I would consider setting up directly in my development environment. As long as Glue docker image is actively maintained, I would always choose the docker setup for exploring new features or quick hack with new glue version.
References